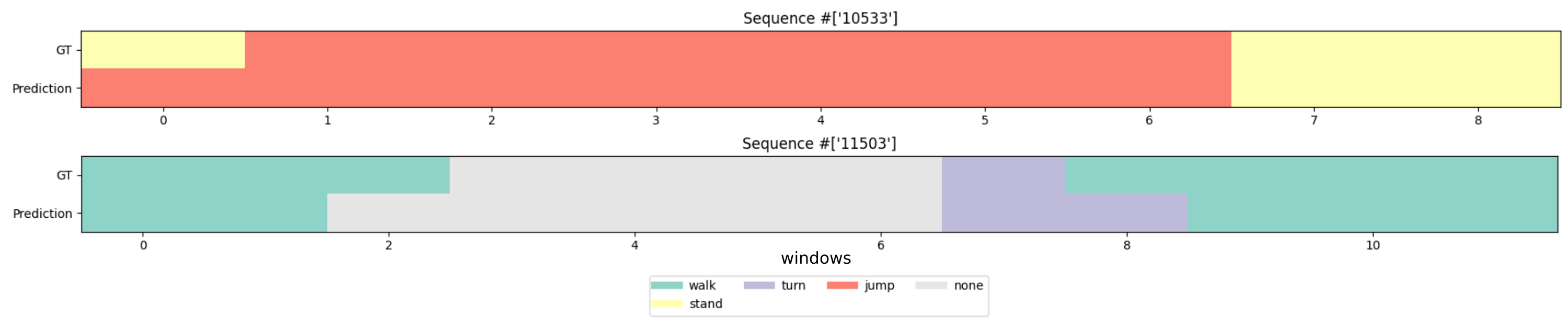
Temporal Action Detection (TAD) necessitates the precise recognition and localization of actions within untrimmed videos. Current approaches predominantly focus on single-view systems, which are constrained by a single perspective during both training and inference. Furthermore, existing skeleton-based methods typically rely on local temporal windows, often failing to capture long-range dependencies between these windows. To address these limitations, this paper introduces a novel multi-view framework designed to leverage complementary perspectives for more accurate action boundary detection. Our method employs a specialized encoder to extract motion features from localized temporal windows. These features are then integrated by HydraView, a multi-view and multi-scale temporal encoder that aggregates information across different perspectives to perform frame-level action detection. To mitigate the high computational overhead associated with managing long sequences in multi-view systems, we build HydraView upon the recent Mamba architecture, ensuring linear scaling and reduced inference time. Experimental results demonstrate that our approach outperforms several state-of-the-art TAD models on the BABEL and PKU-MMD datasets. Our code and pre-trained models will be made publicly available.